
Why imitation learning?
Deep learning is pushing forward the frontier of tasks possible with robotic arms, making previously impossible tasks, like folding shirts or tying shoelaces, possible. Manipulation tasks are very difficult to model due to the complexity of contact forces, deformable objects, and visual appearance in the real world, which is why learning based methods, which can implicitly learn these models from lots of data, are giving state of the art results. Imitiation learning (IL), where the model learns from expert demonstrations of a task, and reinforcement learning (RL), where the model explores by trial and error, are techniques that have both had success. Imitiation learning tends to be the dominant approach, as the expert demonstrations can much more quickly and efficiently get the model to learn desired behaviour, and the reward functions needed for RL can be very complex to define by hand, especially as tasks get more sophisticated.
Imitation learning has two main approaches: behavioural cloning (BC) and inverse reinforcement learning (IRL). BC is a simple supervised learning technique, where given the current observations of the robot and environment, the model is trained to predict the next action the expert takes. This breaks down when observations not in the data are encountered at test time, which is a common occurrence if things go a little off track - and techniques have been developed to help this. IRL involves training a network to estimate a reward function from the expert’s actions, i.e. deducing the “goals” that are shaping the expert’s decisions. A standard RL algorithm can then be used on this estimated reward function to find the optimal policy.
Goal
To get my feet wet with imitiation learning for robotic manipulation, I decided to opt for the simplest possible approach, doing simple behavioural cloning, using a basic multilayer perceptron (MLP) as the actor network (i.e. the network learns to make decisions), and pretrained Resnet-18 networks for visual perception. The chosen task was simply to grasp (and optionally lift) a block in simulation, and I generated the demonstrations using a script (instead of recording human teleoperation), allowing for quick data collection and iteration.
Environment setup
In previous blog posts, I have been playing around with an Xarm Lite6, and I was keen to get this project running in real life on the Lite6 I had access to. However, the Mujoco Menagerie model did not have a gripper modelled for it, so I had to go out and add it to the model myself. This ended up being a bit more time consuming than expected (as usual) but I did gain good insight into how Mujoco’s modelling works, and I was able to contribute the model back to the community.
The environment was set up with Gymnasium, as is common for IL/RL projects , and I took inspiration from state of the art repositories like ACT and LeRobot. I also wanted to have my environment compatible with LeRobot for the future. I chose a simple red cube for the object to grasp, so that it stood out and was simple to grasp with the limited gripper. The gripper is a little unusual in that it is actuated by compressed air, so it’s an all or nothing actuation which I modeled as a discrete variable with 3 states - off, closed and open. This was embedded with a 3-bit one hot encoding for the network.
- Action space: 7DOF - 6 joint angles and 1 gripper action
- Observation space: 6 joint angles, 3rd person camera (320x240), 1st person wrist camera (320x240)
Data collection
Because the task is simple, and the cube position is known in simulation, it was easiest to write a script to generate the training data. This ended up being incredibly useful as, even thought the initial set up took a while, being able to rerecord data at the press of a button made it really easy to iterate and test new ideas. The script took the following steps:
- Generate and follow a screw trajectory from the intial (random) position to just above the box
- Open the grippers and lower down around the box
- Close the grippers once at the necessary height
- Lift upwards to a predetermined height
Instead of adding collision avoidance to the script, I decided to take the quick and dirty option of simply discarding/redoing any trajectories that failed. They failed around 20% of the time, so it was no big deal just to generate a few more and get on with the imitation learning.
Two important steps to ensure the validity of the data were:
- Run an open loop replay, i.e. play the recorded actions from a trajectory in the environment, and ensure that the grasp is reproducible with the data. This is great for catching any bugs in the data collection and/or environment setup - we can’t train a successful model on data that can’t reproduce the result!
- Plot/visualise the recorded data. Make sure the camera views take in the full scene, and the joint angles look correct. I spent a week training with no results, until I plotted the trajectories and noticed that the joint angle observations were static (a bug in the environment where I needed to do a deepcopy).
Method
- For maximum simplicity, a simple behavioural cloning approach was taken. The model is trained on individual observation-action pairs, in random order, to minimise the loss between the predicted next action and the recorded next action. The next action was chosen to be the one 0.1s ahead.
- The model architecture used for the actor netework was a plain MLP, usually around a size of 64x64x64, with ReLU activation. For perception, a pretrained Resnet-18 was used for each camera, with weights unfrozen.
- Two cameras were used in the data. A third person side-on camera, and a 1st-person wrist camera fixed to the gripper.
- Joint angles were used the observation and action space. Cartesian coordinates could be easier for the model to learn, but the inverse kinematics is susceptible to singularities, and the model should be able to learn the robot kinematics with enough demonstrations. It would be good to compare the differences in future, but state of the art approaches have been successful with both.
- Joint angles were normalised to the range [-1, 1] for the model

Experiments and results
Initial mistakes
For brevity, I won’t bother going through the results whilst I was testing the system with flaws that were obvious in hindsight. But so you don’t make the same mistakes, I will briefly touch on them:
- As previously mentioned, the joint angle observations weren’t being recorded correctly. Validate the data by running open loop replays, and plotting it!
- I was training on the current action instead of the next action. This directs the model’s action towards the goal, stops it getting into a potential feedback loop, and is done in all IL papers.
- The vision encoder weights were frozen. I thought “it’s already learned good visual representations, why bother training?”, but of course fine tuning to a task always results in better performance. Thankfully this great tutorial pointed this out specifically for robotic manipulation, i.e. models perform much better when fine tuned on data from the target domain - it learns to recognise the object.
Making the task more tractable
These were some other steps I took to maximise the model’s chances
- Using a wrist camera. This is important, and I noticed an improvement with how close the robot could get to the block when it came in view of the wrist camera. The 2D side cam image doesn’t provide great information on the relative positioning of the gripper to the object, especially in the depth axis. Papers often find much better performance with a wrist camera. This is just extra, useful information that can (or at least, should) only help the model.
- Object choice. A cube is easy to grip. The larger, the better, and in a contrasting colour, to make it easier for the model to see where the object is.
Evaluation
The rollouts shown are controlled at 30Hz, and are each 5s long. For each experiment, 15 rollouts are done, and the average reward is recorded for each. The mean and standard deviation of the average reward across all rollouts are then used to evaluate performance on each task. The videos from the rollouts are concatenated into one video, i.e. a 75s video where each 5s is a different rollout. The reward structure is as follows:
- 0-1 (continuous) - distance from grippers to object, where 0 is >10cm away, 0.5 is 5cm away, and 1 is touching; and grippers not touching ground
- 2 - one gripper touching the object and grippers not touching ground
- 3 - two grippers touching the object and grippers not touching ground
And additionally for the lift task:
- 4 - two grippers touching the object, grippers not touching ground, and object not touching ground (i.e. lifted)
- 5 - two grippers touching the object and grippers above 20cm
But as you will see we hardly every get to 2 let alone higher.
Experiment 1: Task/data choice
To state the obvious, because we are learning by imitation, the data we choose dictates the behaviour the model learns. If we train on a single trajectory, it will learn to imitate that trajectory. If we train on a diverse set of trajectories, hopefully it will learn to operate in diverse circumstances.
Grasp and lift with randomised arm and cube position
I started with this task because I thought it would be fairly simple. By randomising the position of the object and the arm, I hoped it would force the robot to learn how to detect the object, and how to control the arm, in a generic way. It turned out to be a little more difficult than expected, and I was unable to get it to perform well.
It seemed to commonly fail by getting stuck, usually up high or just above the object, and never actually lowering down to the block. I hypothesised that this was due to the multimodality of the task - i.e. the reaching down to grasp and lifting up are two distinct/opposite actions, and it was averaging them out. Thus I decided to make the task easier by just focussing on the the grasping portion.
Grasp only - randomised trajectories
Unfortunately this did little to improve performance. Clearly there were bigger issues than the multimodal data. The policy seemed to only vaguely go in the direction of the object. So to make the task easier again, I decided to hone in on a fixed task instead of randomly initialising. Here is how well the same model as before, with 50 randomised trajectories, does on the fixed task. It gets to roughly the right location, but never manages to actually pick up the object.
Grasp only - fixed trajectory
To make things simpler again, I scaled it back to a single, fixed task, where the starting joint angles and object position are the same every time. This is a scripted trajectory showing the fixed task:
I first tried a model trained on the randomised trajectories to see how well and consistently it performed on the fixed task:
It shows some promise, but it can’t quite reach all the way down and pick the object up.
Thus to make it easier again, I trained a model with only data of the fixed trajectory. This gives an improvement, it gets near to the block consistently, and almost manages to grasp it. This is obviously a pretty limited model as it can only (barely) accomplish one task, so offers no advantage over a script.
Mixture of random and fixed
In order to see how the network would respond to adding in some randomised trajectories, I experimented with different blends of fixed and random trajectories in the data. Ideally, the model would be able to accomplish the fixed task easily as it is in the training data, and then adapt to some more random tasks. Unfortunately, this adaptation never occurred, and the models struggled with the fixed task at any level of randomised trajectories being blended in, as seen in these rollouts:
This is a lot to take in at once, so here are the evaluation results. I’ve included the results at epoch 10 and 20 as they differ a bit. As a reminder, the evaluations are done on 15 rollouts. These are all done on the fixed task, except the last column which is done on randomised positions.
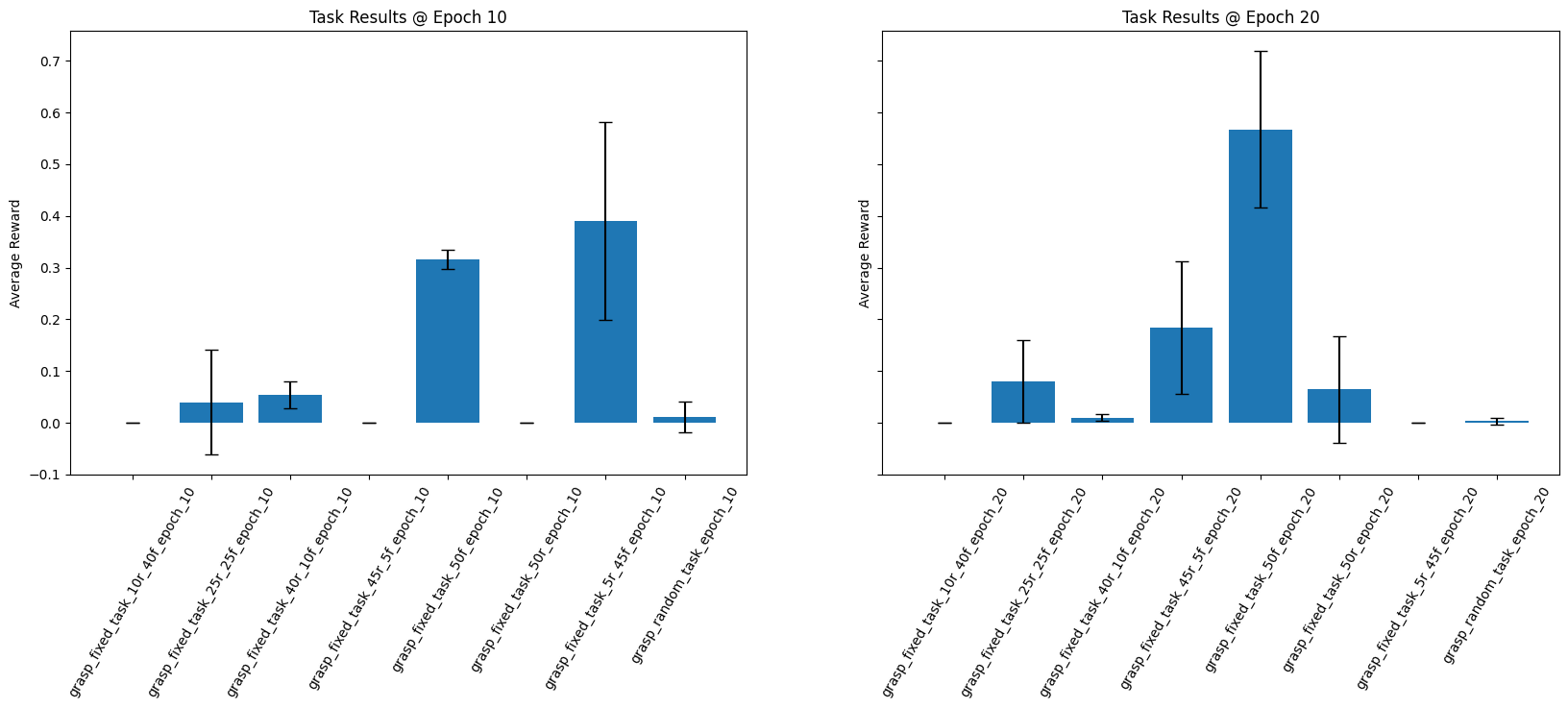
At epoch 10, the blend of 5 random, 45 fixed does slightly better than the purely fixed task (though with high variance). However, at epoch 20 it managed to unlearn everything and get 0 reward. The purely fixed trajectory data managed to improve with more epochs, and achieved the best overall performance. The 45 random, 5 fixed task managed to have a small amount of success at epoch 20, and you can view its performance in the first of the videos above.
Overall, the model was unfortunately unable to generalise to random tasks. Some of the numerous other experiments attempted are included in the appendix, including training on a larger dataset, for longer, and with larger networks.
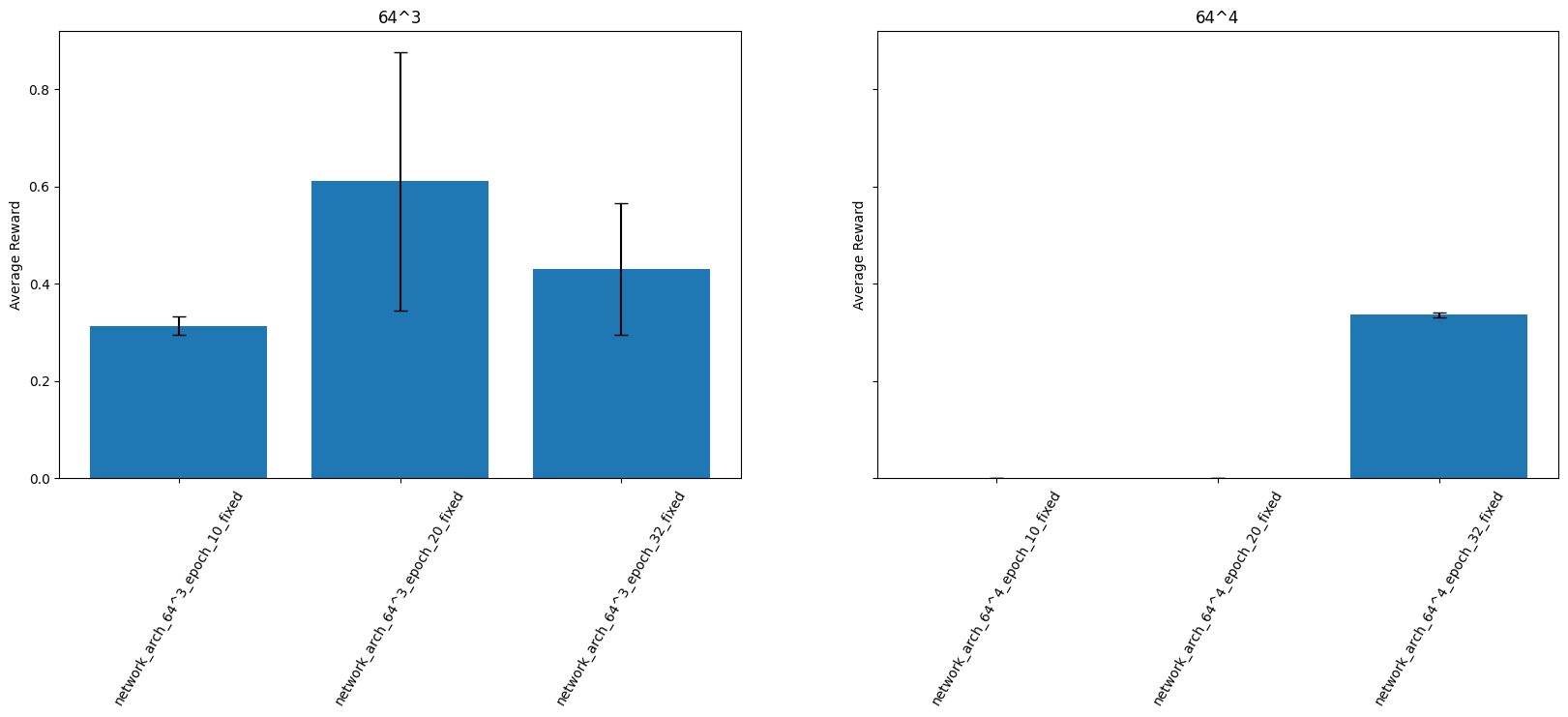
Model architecture
I didn’t manage to get much improvement in performance with different model architectures. Here’s a comparison with an extra hidden layer to make the MLP 64x64x64x64 (referred to as 64^4 in the diagram). More testing on architecture for the random task is included in the appendix.
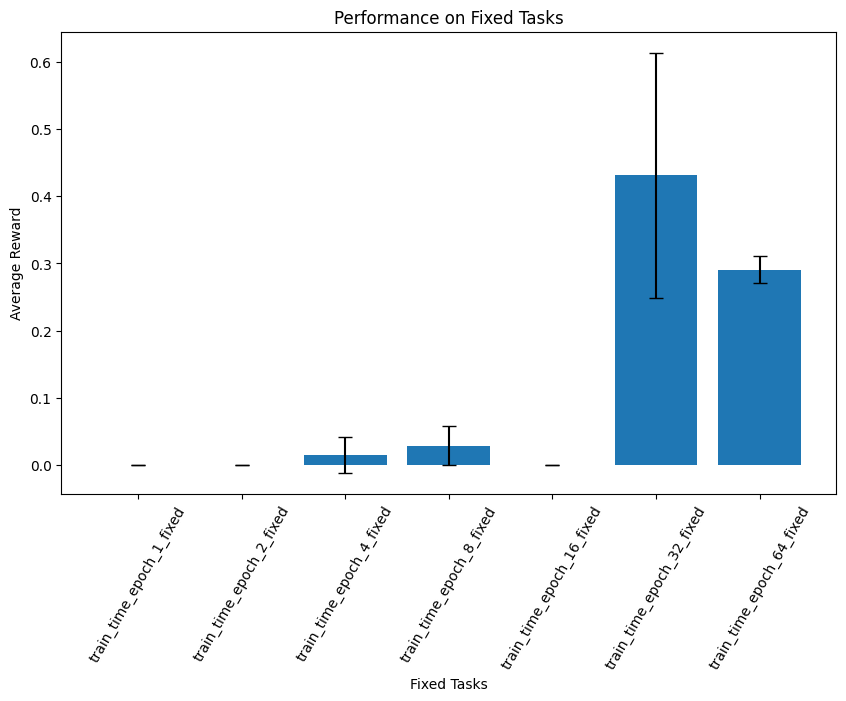
Training time
Increased training time on the purely fixed dataset resulted in improving performance.
The results are graphed here:
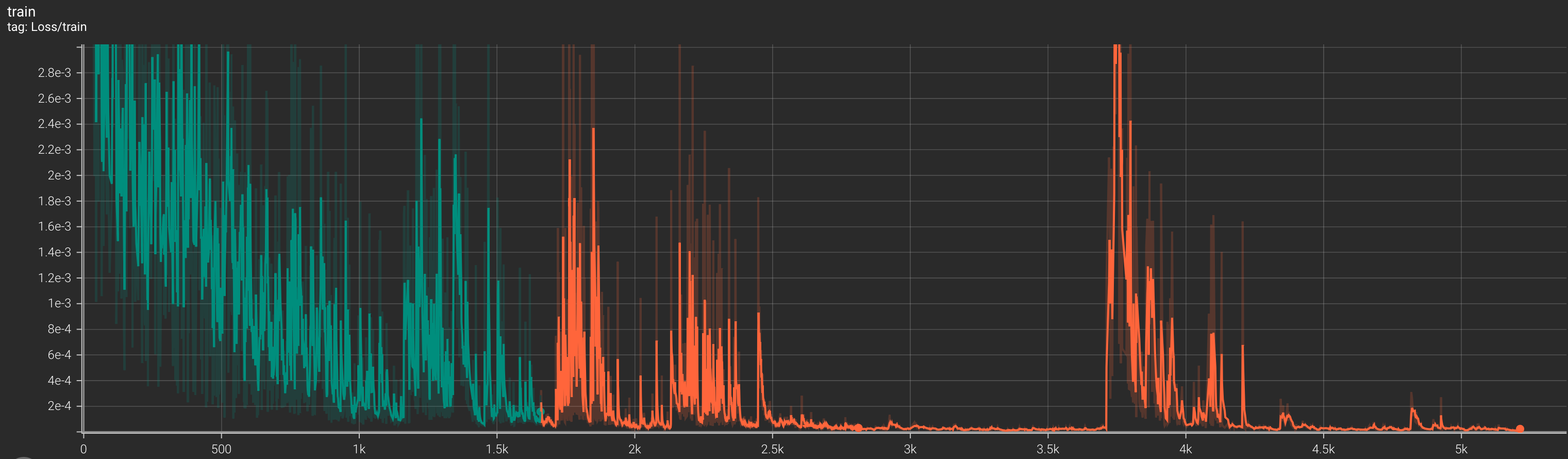
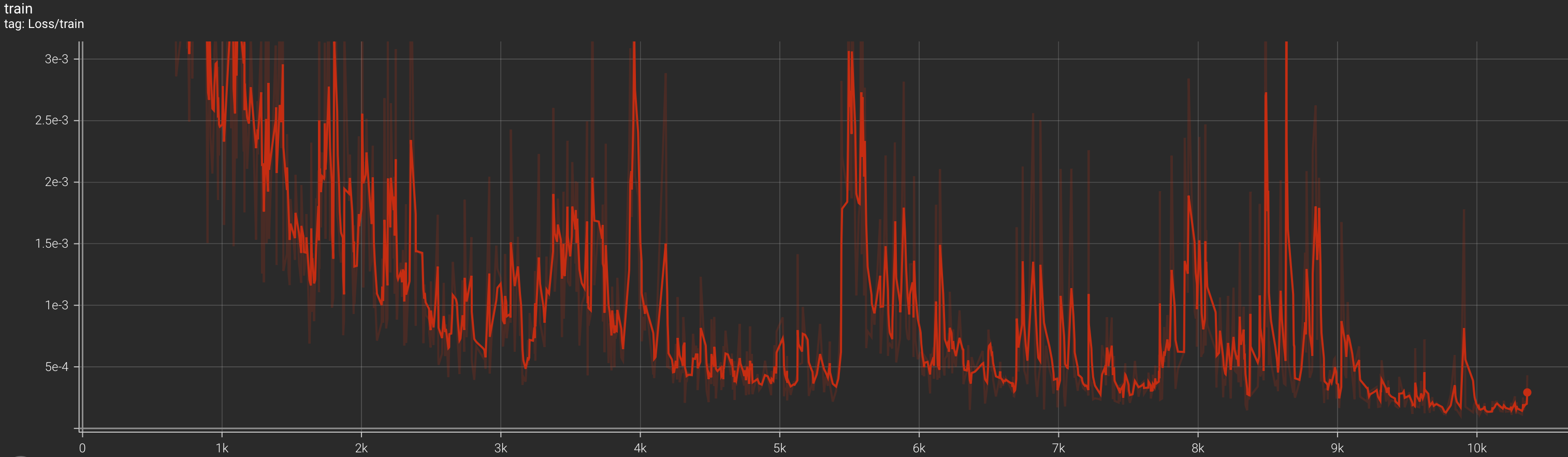
And the loss here. We see a strange spike in loss around 3.7k steps (~45 epochs)
Discussion
Overall, the model was able to learn a single policy ok, but extrapolating beyond that was not achieved. Observing the performance on the randomised task, it learns to lower the arm, and seems that it is sometimes able to go towards the block, which gives me hope that it has able to perceive the object to some extent. The two failure modes that seem to occur, are that it will head towards a default position (down and to the right) regardless of where the object is, or that it gets stuck in a random location. After experimenting with more data, more parameters, and longer training time, and getting no sign of improvement from any of these, it seems there is some more fundamental issue preventing learning the desired behaviour.
Upon inspection, the data seems good, with clear visual features, a contrasting background, and success in open loop replays. However, it is still possible that good visual features are not being learned. Perhaps some self-supervised learning/fine-tuning (e.g. BYOL) on the vision encoder would help.
I don’t think MLP-MSE is the wrong approach, as it has found moderate success in previous papers like BC-Z (Jang, Irpan). The approach is definitely limited when it comes to multimodal data, but it seems the data is fairly unimodal - just move directly to the block and grasp. There are not fundamentally different methods ways of doing this in the data, or steps executed in different orders. However, I do often notice behaviour where the arm seems to default to going down and to the right, which makes it seem like it may be just learning the average of all the data. Perhaps it is not being well conditioned on the goal or observations.
The model also learns and predicts based on the observations at a single time step. Because a successful trajectory involves stringing together a coherent sequence of individual actions, it may benefit from being trained on/acting on a sequence of observations. This is a crucial part of state of the art approaches like ACT, and Diffusion. This could conceivably be done by feeding the model the previous n observations at a time, or by using a sequential model like an LSTM or transformer.
Additionally, perhaps the naive behavioural cloning technique used here is insufficient, as we see the arm occasionally get stuck in certain positions. This is probably a manifestation of a common issue with behavourial cloning, where the model encounters observations at test time which were not in the training dataset. For example, if the arm goes into a position where there is no data for it to imitate, its behaviour will be unpredictable - usually it will freeze. Methods like DAgger and inverse reinforcement learning were designed to deal with this shortcoming, so may be worthwhile avenues to explore.
One other concerning thing I noticed was the irregularity of the loss curve, where for every training run, there would be spikes where the loss would increase significantly and go back down. I’m not sure why the loss would approach zero for a while, and then dramatically spike like this. Perhaps it is learning rate related? I think this may have also affected the performance of the model at different epochs, where instead of monotonically increasing performance with increased training time, some checkpoints would do worse and then get better again.
For a next step, to validate the environment and data, I’m considering trying a nearest neighbours approach like VINN. This policy simply selects the closest observations from the dataset and applies the corresponding action. This makes it much more interpretable, and the choice of closest observation may give intuition on where things are going wrong. Alternatively, it may be worth just substituting in ACT/BeT/Diffusion to see if it works.
Conclusion
While the results of this experiment were lacklustre, especially for the amount of time invested, it was still a valuable learning experience. From the simulation, to the infrastructure, to the mistakes found, to the many training runs and hyperparameter sweeps tried, it served as a way to begin to understand imitation learning and robotic manipulation from first principles. It gave me a lot of admiration for pioneers in the field, who have managed to make progress in such an open-ended and high-dimensional space.
I’m excited to try out some more state of the art approaches - to validate the environment, to learn deeply about them, and to hopefully show me why the current approach does not work. RL would also be very interesting to try, but it would no doubt come with its own set of challenges.
Appendix
A lot of effort was expended trying to get the model to work on the randomised task. Here are some of the things I tried.
Dataset size
I tried doubling the dataset from 50 to 100 randomised trajectories, and expected that the model would have a much easier time generalising with all this extra data. Similarly, I also tried halving the dataset to 25. I also doubled/halved the number of epochs of training so that the models are compared at the same training step, and the larger datasets do not get the unfair advantage of extra training. For completeness, I then took the largest dataset (100) and trained it to 40 epochs so we cold also compare them at the same epoch, giving the model more time to learn the distribution of the larger dataset. Alas, the results were quite inconsistent and counterintuitive.
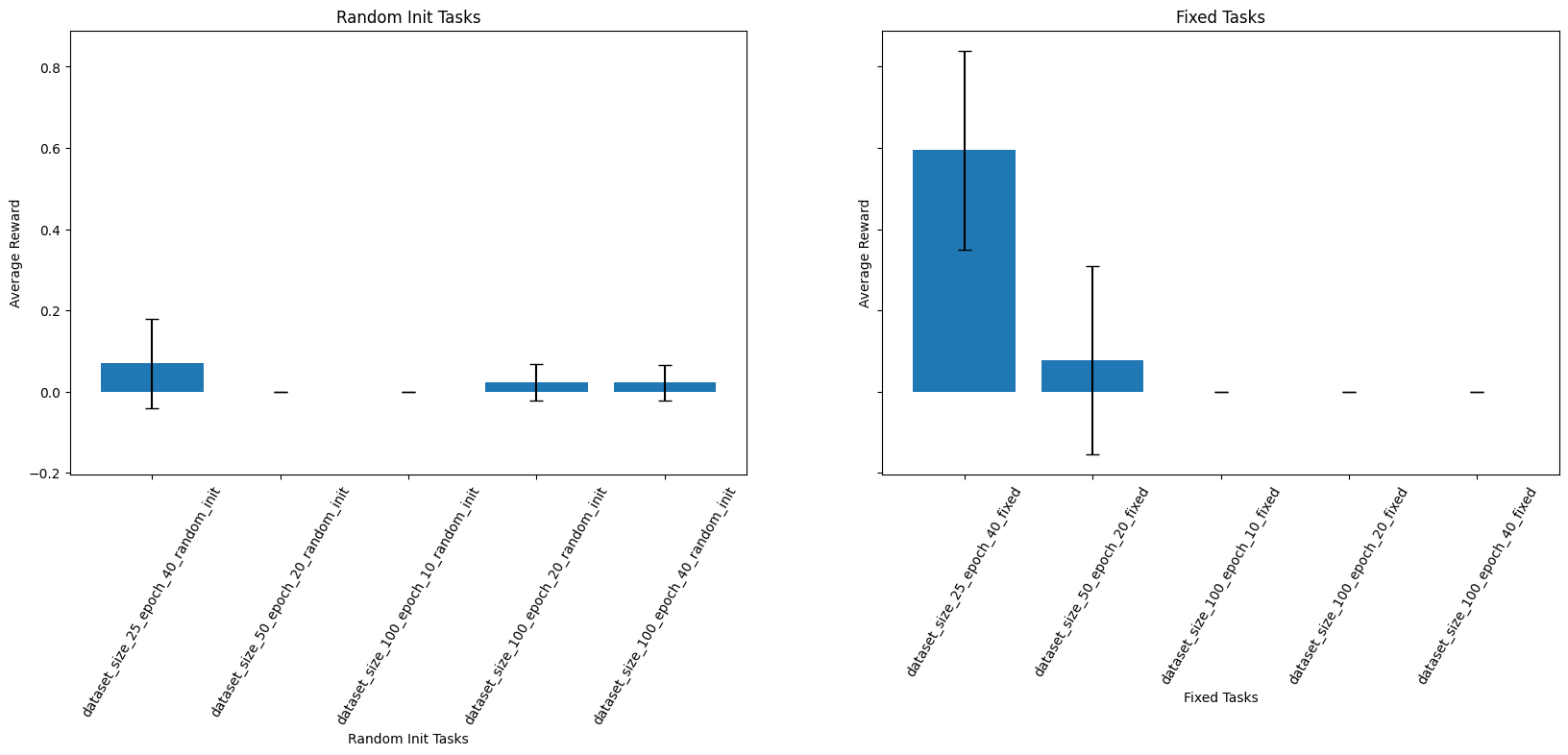
For the random tasks, the average rewards are all very low and with high variance, so there’s probably no indicators of any performance. For some reason, the smallest dataset did far and away the best on the fixed task. To me this doesn’t make a lot of sense - these models are trained on randomised trajectories, so I would expect a model trained on a larger dataset to be able to adapt to any task, including the fixed task, better. Perhaps the small dataset got lucky with demonstrations that were somewhat similar to the fixed task, so it was able to transfer more easily. Whereas, models trained on the larger dataset are just unable to learn the distribution well, thus fail at everything. This got me thinking that perhaps a larger network was needed…
Network architecture
In the case that learning was limited by the network size, I tried adding up to two more hidden layers i.e. from 64x64x64 to 64^4 and 64^5. I then trained them on the dataset of 50 randomised trajectories, and compared the results on the random and the fixed task, at 20 and 40 epochs.
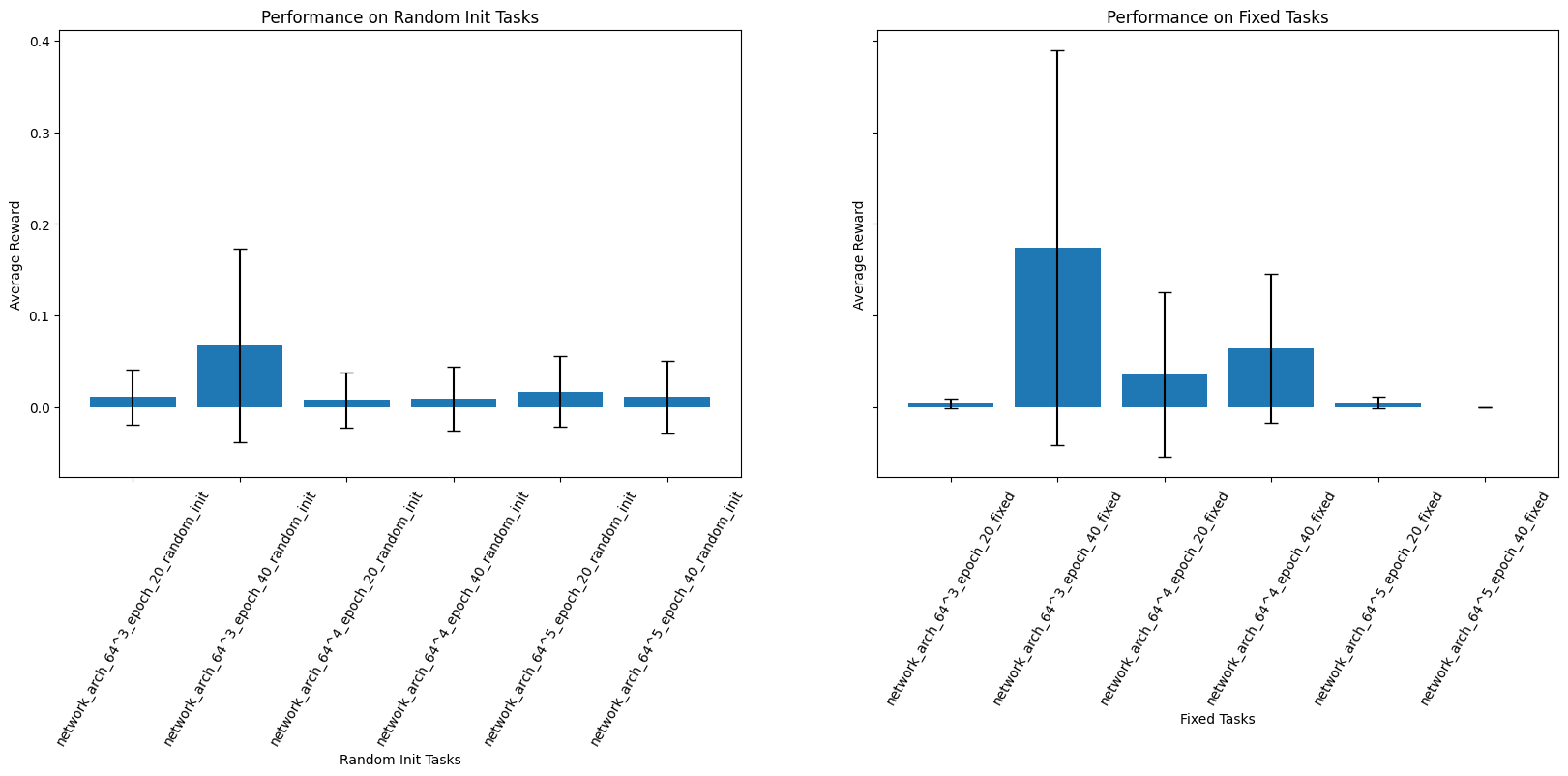
There was no clear result here, results were poor across the board.
All in
Just to give the randomised task the best chance, I put together the largest dataset (100), the largest model (64^5) and trained for 60 epochs. The policy evaluated across every 10 epochs is shown here, on the random and the fixed task:
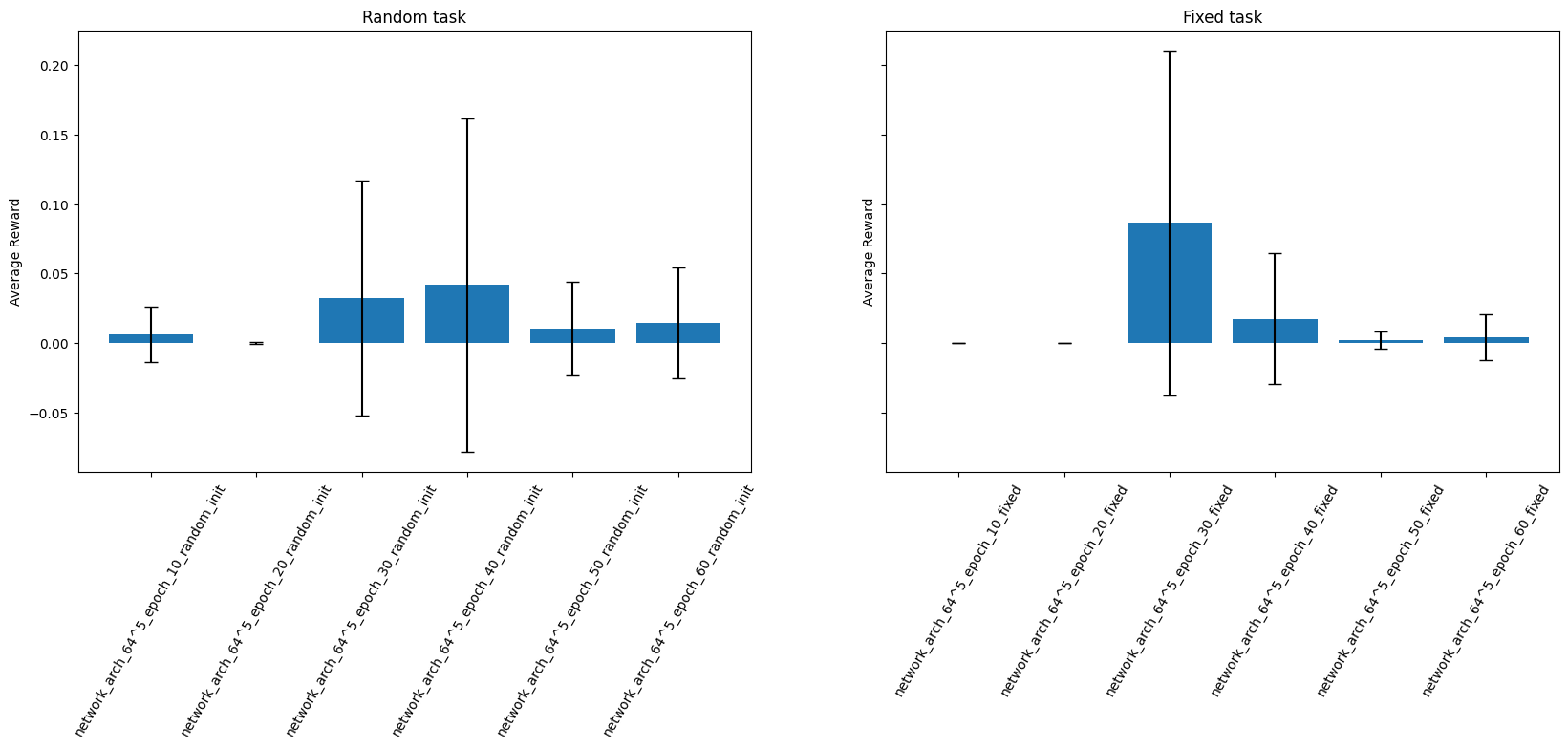
All rewards are very low and with high variance, so it seems the learned policy is not useful, although the loss is clearly decreasing overall.
Here are some samples:
Velocity Observations
I added joint velocities to the observation space, to see if some information about the relative motion of the arm was useful. I tried it on a 64x64x64 MLP and a 64^5 MLP, and all I got for both was chaos:
Code
The code for the everything is available here: https://github.com/eufrizz/robotic_manipulation.
I haven’t taken the time to make it clean and readable to a release-ready standard, because that takes time and I doubt anyone is going to want to recreate this very average result. But if someone is interested, I’m happy to clean it up and give some pointers, just shoot me a message.