
Deep learning a robotic manipulation policy from scratch can be a difficult task, as it requires nailing the algorithm, the implementation, the model and the data, as is wonderfully explained in this blog post. Compounded by the delay in the debugging cycle due to model training time, this 4-dimensional iteration to a good solution makes machine learning a pain in the back - traditional software development only requires iteration on the algorithm and implementation, with instantaneous feedback. Typically, you need a good starting point and good intuition to make inroads into ML research.
In imitation learning for robotic manipulation, we are also usually solving two coupled problems: learning good visual features, and learning good actions.
In the paper The Surprising Effectiveness of Representation Learning for Visual Imitation (Pari et al., 2021), or VINN (Visual Imitation through Nearest Neighbors) for short, a simple solution is provided to break down the complexity of these steps. While it may not be as flexible and high-performing as state of the art deep-learnt methods, it is a great way to check that the environment, data and visual features are good before moving on to more sophisticated methods. It also forms a great baseline for the performance of subsequent methods.
The VINN method
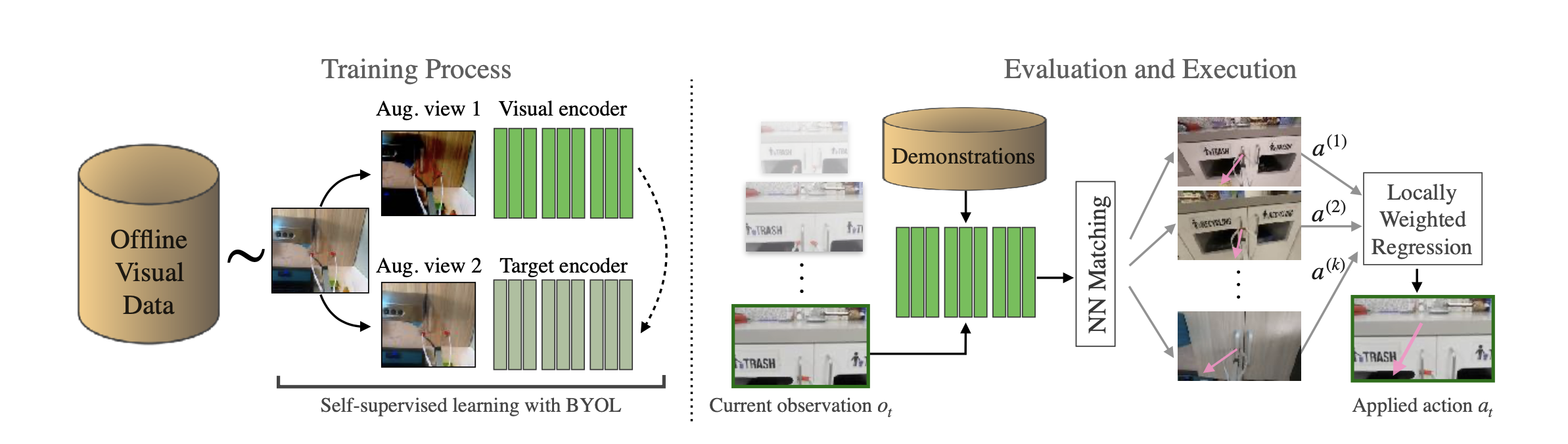
At the highest level, given a dataset of expert demonstrations of a task, the vision learning is separated from the action learning. Visual features are fine tuned on the dataset from an ImageNet-pretrained ResNet model with the amazingly simple self-supervised Bootstrap Your Own Latent (BYOL) method. Fine-tuning the visual encoder on the data distribution found in the task is an important step for good quality visual features, as there is usually a significant domain shift from ImageNet pretraining data to robot data. The beauty of BYOL is that it learns good features through data augmentation (no labels or contrastive pairs needed), thus it requires no work aside from just going and training your vision model on the dataset - instantly applicable to any task!
Another major benefit of the separation of vision learning is that you can iterate on the policy and the data without having to retrain the vision encoder, as long as the environment/objects/positions involved are the same. This allows you to add more data, change the action type (i.e. joint positions vs cartesian pose, relative vs world frame), or even try different tasks without once waiting for a vision model to retrain, a huge time and compute saver.
On the action side, VINN keeps things really simple by avoiding learning altogether and simply doing a nearest neighbour search in the dataset. That is, at test time, the closest visual match for the current vision input in the dataset is found (i.e. the nearest neighbour), and the corresponding action is chosen. This is achieved by saving the vector embeddings of all the vision data in the dataset - in other words, doing a single pass of inference on the dataset. At test time, the current visual input is encoded, and a nearest neighbour vector search is done. Simple, but effective!
My implementation
Because the method is so simple, it was honestly easier to reimplement for my environment than to adapt from the authors’ repository.
I trained the Resnet-18 vision encoder on the gripper cam data, 100 demos * 200 frames each = 20 000 total, for 100 epochs, starting from ImageNet pretrained weights. Because the scene and lighting are static in my simulation, I probably could have gotten away with less, but no harm in having better features. The original paper used a Resnet-50, but the smaller model did just fine here. And with the magic of BYOL, after a couple of hours I had features!
Here are some visualisations for those that are curious:



For nearest neighbours, the authors’ implementation involved calculating the L2 distance between each input image (at test time) and every example in the dataset. I found this annoyingly slow, and I was also concerned about the curse of dimensionality in the 512-d space, so I opted for an approximate vector search courtesy of USearch, with cosine similarity as the distance metric. Not only was it 500x faster, but it took only 4 lines to implement. Actions are calculated the same way as the paper using locally weighted regression, i.e. getting the nearest k neighbours to the query image, and taking the weighted average of the associated actions, with weightings being the softmin of their distances.
In order for the chose task of picking up a randomly placed block to be feasible with the nearest neighbours approach, end-effector-centric commands had to be used. In previous blog posts, I was using joint positions as the actions, but it is clear that at test time, the block is never going to be in exactly the same place as it was in any rollout in the training data, so using absolute positions will never generalise. Thus I updated the environment to support end-effector-frame cartesian velocities as actions. The scripted trajectory generator I am using for data collection also needed conversion from world-frame positions to end-effector-frame velocities.
For data collection from scripted trajectories, I also scaled back the control rate/frame rate from 30Hz to 10Hz, so that there was less repetition in the dataset. Neighbouring frames at 30Hz were very similar from a vision and action perspective at the low speeds involved, so dividing the amout of data to collect and search through by 3 it made it quicker to iterate on without noticeably affecting performance.
Tests
Some useful tests for algorithmic correctness were:
- Making sure scripted trajectories worked well with end-effector-frame velocity control
- Open-loop replays of the recorded actions
- Making sure nearest neighbour search was reproducible
- Take the saved vector embedding of image at given index, run search, and make sure it returns the same index.
- I had a bug where I was shuffling the indices in the dataloader when saving the embeddings, and ended up with vectors not corresponding to the images
- Making sure embeddings were reproducible
- Given an image from the dataset at a known index, or re-rendered from the same joint angles, embed it, run nearest neighbour search, and ensure that the same index is returned
- Make sure the recorded actions are in the right reference frame and behave as expected
- A simple visual check is to take 10 consecutive samples from the dataset, apply their actions to the environment, and visually compare the movement from the gripper cam to the recorded frames.
- I had a bug where I recorded the actions in world frame but applied them in end-effector frame. I noticed the arm was moving in the opposite direction to what I expected, and upon inspection saw that the recorded motion was moving up while the same actions applied to the arm made it move down.
Results
I did not take the time to do a quantitative evaluation of the policy as this was more an exercise in just getting the implementation, visual features and dataset right. The only hyperparameter is k, the number of nearest neighbours to use, and an evaluation of its impact on performance is avaiable in the original paper.
First off, the visual nearest neighbour search works quite well. It is satisfying to visualise the nearest neighbours alongside the current image and see that they are indeed similar - check the gripper cam video below.
If the arm is initialised to a favourable position with some visual texture and not too far from the block, it can do quite well. It also has quite repeatable behaviour, with the same initialisation leading to the same results for at least the first few seconds, especially for lower values of k. The following shows 3 rollouts from a fixed position with k=5:
However, most of the time, the performance is fairly underwhelming. As you can see in the following, without any good visual features to go on, the motion is quite random.
A plot of the actions - end effector linear and angular velocity - are shown here. They are quite spiky, and this is evidenced in the jittery performance.
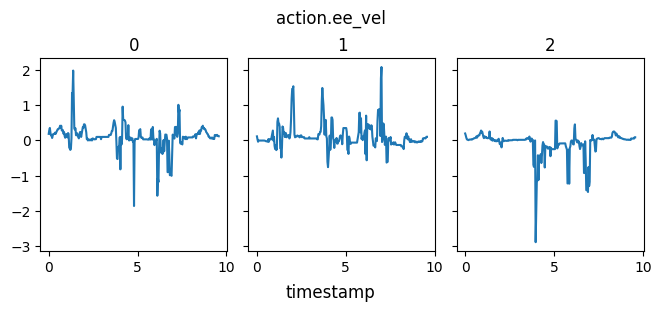
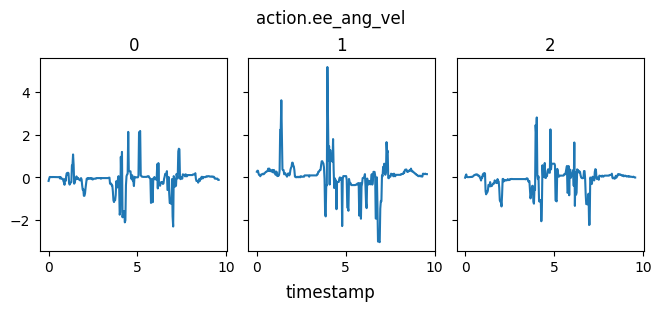
Increasing k to 20 doesn’t make motion very much smoother. It also doesn’t have a noticeable effect on performance, thus performance issues probably are not the result of a poor choice of k.
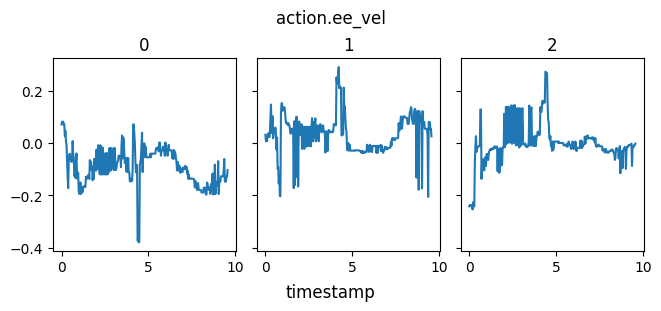
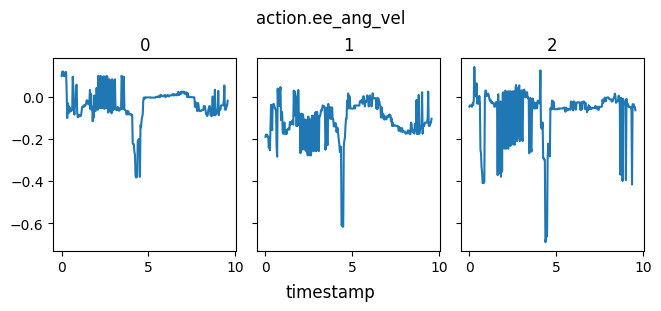
The most common failure mode (~80% of the time) seems to be getting stuck looking up at nothingness, and wandering around aimlessly, as seen in the video.
Discussion
I believe the biggest issue with the current approach is the data quality. The nearest-neighbours method elucidates where there are flaws in the data, which is part of its beauty and its limitations. The current scripted trajectory generator is rather a crude method (it simply follows a screw trajectory from initial position to block position, no collision detection etc.), and while it works for the most part, it does have a few flaws. I noticed the script tends to fail more on cases where the end-effector is initialised looking upwards, or on the opposite side from the block. Thus, these cases are underrepresented in the data and have lower quality actions. When combined with the poor visual features from looking up at the sky, we get the worst of both worlds - a random selection of low quality actions. So, it is probably time to upgrade the script to do motion planning and trajectory optimisation, to create trajectories which are good given any initial conditions, and can provide lots of demonstrations of moving from looking up to looking down and finding the block successfully. There are also a few collisions in the trajectory data which would be avoided with this upgrade.
Another issue with the robot motion arose when moving to cartesian velocity control. I am simply doing damped inverse kinematics to calculate joint velocities, and the robot has a tendency to fold itself up into a pretzel. This would be improved with a regularisation term, to incentivise the arm to be in a comfortable position instead of blindly falling into twisted positions and singularities. Both scripted performance and test time performance would benefit from this!
The environment could also be improved with some more visual texture, especially up high. Instead of being lost looking at the blank sky, why not add some objects (e.g a textured ceiling) to help the nearest neighbour search? A real life environment is likely to have this already.
And of course, bumping up the amount and diversity of data always helps. I noticed a significant improvement going from 100 trajectories to 200 in the dataset, as one would expect. The scripted trajectories make it a breeze to generate more!
Conclusion
Reimplementing VINN was a great way to get demonstrably working visual features for an imitation learning policy, and debug issues in the data and implementation of the environment and arm control. It serves as a good baseline for further experiments with deep learnt policies, and hints for where performance bottlenecks may exist.